









All Exams >
Computer Science Engineering (CSE) >
Operating System >
All Questions
All questions of File Systems for Computer Science Engineering (CSE) Exam
On a disk with 1000 cylinders, numbers 0 to 999, compute the number of tracks the disk arm must move to satisfy all the requests in the disk queue. Assume the last request serviced was at tracks 345 and the head is moving towards track 0. The queue in FIFO order contains requests for the following tracks. 123, 874, 692, 475, 105, 376. Perform the computation using C-SCAN scheduling algorithm. What is the total distance?- a)1219
- b)1009
- c)1967
- d)1507
Correct answer is option 'C'. Can you explain this answer?
On a disk with 1000 cylinders, numbers 0 to 999, compute the number of tracks the disk arm must move to satisfy all the requests in the disk queue. Assume the last request serviced was at tracks 345 and the head is moving towards track 0. The queue in FIFO order contains requests for the following tracks. 123, 874, 692, 475, 105, 376. Perform the computation using C-SCAN scheduling algorithm. What is the total distance?
a)
1219
b)
1009
c)
1967
d)
1507
|
|
Sanya Agarwal answered |
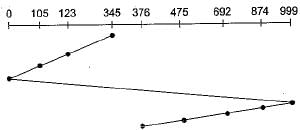
∴ Total distance covered by the head
= (345 -123) + (123 -105) + (105 - 0) + (999 - 0)
+ (999-874) + (874-692) + (692-475) + (475 -376)
= 222 + 18 + 105 + 999 + 125 + 182 + 217 + 99
= 1967

Let's say there are seven requests: 16, 24, 43, 82, 140, 170, and 190. Additionally, the disc arm is supposed to travel "towards the larger number" while the read/write arm is at 50. What is the total seek time?
Correct answer is '332'. Can you explain this answer?
Let's say there are seven requests: 16, 24, 43, 82, 140, 170, and 190. Additionally, the disc arm is supposed to travel "towards the larger number" while the read/write arm is at 50. What is the total seek time?
|
|
Nishanth Mehta answered |
In one direction only. In this case, the disc arm will start at a certain position and move towards the nearest request in that direction. Once it reaches that request, it will continue in the same direction to the next closest request.
To determine the total distance traveled by the disc arm, we need to know the starting position of the disc arm. Let's assume the starting position is 50.
Here is the order in which the requests will be serviced and the distance traveled at each step:
1. Start at position 50.
Distance traveled: 0 (since the arm is already at the starting position)
2. Move to request 43.
Distance traveled: 7 (from 50 to 43)
3. Move to request 24.
Distance traveled: 19 (from 43 to 24)
4. Move to request 16.
Distance traveled: 8 (from 24 to 16)
5. Move to request 82.
Distance traveled: 66 (from 16 to 82)
6. Move to request 140.
Distance traveled: 58 (from 82 to 140)
7. Move to request 170.
Distance traveled: 30 (from 140 to 170)
8. Move to request 190.
Distance traveled: 20 (from 170 to 190)
Total distance traveled by the disc arm: 208 units.
To determine the total distance traveled by the disc arm, we need to know the starting position of the disc arm. Let's assume the starting position is 50.
Here is the order in which the requests will be serviced and the distance traveled at each step:
1. Start at position 50.
Distance traveled: 0 (since the arm is already at the starting position)
2. Move to request 43.
Distance traveled: 7 (from 50 to 43)
3. Move to request 24.
Distance traveled: 19 (from 43 to 24)
4. Move to request 16.
Distance traveled: 8 (from 24 to 16)
5. Move to request 82.
Distance traveled: 66 (from 16 to 82)
6. Move to request 140.
Distance traveled: 58 (from 82 to 140)
7. Move to request 170.
Distance traveled: 30 (from 140 to 170)
8. Move to request 190.
Distance traveled: 20 (from 170 to 190)
Total distance traveled by the disc arm: 208 units.
A programmer handles the file allocation in such a way that n+1 blocks are utilized if a file needs n blocks, with the first block including index information. Which file allocation method is used?- a)Contiguous file allocation
- b)Linked file allocation
- c)Chained file allocation
- d)Indexed file allocation
Correct answer is option 'D'. Can you explain this answer?
A programmer handles the file allocation in such a way that n+1 blocks are utilized if a file needs n blocks, with the first block including index information. Which file allocation method is used?
a)
Contiguous file allocation
b)
Linked file allocation
c)
Chained file allocation
d)
Indexed file allocation
|
|
Kritika Ahuja answered |
Understanding Indexed File Allocation
The scenario described involves utilizing n+1 blocks when a file requires n blocks, indicating that one additional block is used for storing index information. This directly points to the Indexed File Allocation method.
Key Characteristics of Indexed File Allocation:
- Index Block Usage: In indexed file allocation, one block is dedicated to storing the index of the file. This index contains pointers to the actual data blocks where the file's contents are stored.
- Direct Access: The presence of an index block allows for direct access to the file's data blocks, enabling efficient retrieval and modification of data.
- Flexibility: It provides flexibility in managing file sizes, as the index can be easily updated when blocks are added or removed.
- Reduced Fragmentation: Unlike contiguous allocation, indexed allocation can help reduce external fragmentation since file blocks can be non-contiguous.
Comparison with Other Methods:
- Contiguous File Allocation: This method requires all blocks to be allocated in a contiguous manner, without the need for an index block.
- Linked File Allocation: In this method, each block contains a pointer to the next block, and does not use an index block.
- Chained File Allocation: Similar to linked allocation, but focuses on a chain of blocks rather than an index.
Conclusion:
Given the requirement of using n+1 blocks, with the first block storing index information, the correct answer is indeed option 'D' - Indexed file allocation. This method efficiently manages files by organizing data block pointers, allowing for quick access and modification while minimizing fragmentation.
The scenario described involves utilizing n+1 blocks when a file requires n blocks, indicating that one additional block is used for storing index information. This directly points to the Indexed File Allocation method.
Key Characteristics of Indexed File Allocation:
- Index Block Usage: In indexed file allocation, one block is dedicated to storing the index of the file. This index contains pointers to the actual data blocks where the file's contents are stored.
- Direct Access: The presence of an index block allows for direct access to the file's data blocks, enabling efficient retrieval and modification of data.
- Flexibility: It provides flexibility in managing file sizes, as the index can be easily updated when blocks are added or removed.
- Reduced Fragmentation: Unlike contiguous allocation, indexed allocation can help reduce external fragmentation since file blocks can be non-contiguous.
Comparison with Other Methods:
- Contiguous File Allocation: This method requires all blocks to be allocated in a contiguous manner, without the need for an index block.
- Linked File Allocation: In this method, each block contains a pointer to the next block, and does not use an index block.
- Chained File Allocation: Similar to linked allocation, but focuses on a chain of blocks rather than an index.
Conclusion:
Given the requirement of using n+1 blocks, with the first block storing index information, the correct answer is indeed option 'D' - Indexed file allocation. This method efficiently manages files by organizing data block pointers, allowing for quick access and modification while minimizing fragmentation.
Consider two files systems A and B , that use contiguous allocation and linked allocation, respectively. A file of size 100 blocks is already stored in A and also in B. Now, consider inserting a new block in the middle of the file (between 50th and 51st block), whose data is already available in the memory. Assume that there are enough free blocks at the end of the file and that the file control blocks are already in memory. Let the number of disk accesses required to insert a block in the middle of the file in A and B are nA and nB respectively, then the value of nA + nB is_________.
Correct answer is '153'. Can you explain this answer?
Consider two files systems A and B , that use contiguous allocation and linked allocation, respectively. A file of size 100 blocks is already stored in A and also in B. Now, consider inserting a new block in the middle of the file (between 50th and 51st block), whose data is already available in the memory. Assume that there are enough free blocks at the end of the file and that the file control blocks are already in memory. Let the number of disk accesses required to insert a block in the middle of the file in A and B are nA and nB respectively, then the value of nA + nB is_________.
|
|
Sudhir Patel answered |
Contiguous allocation:
Contiguous allocation occurs when the blocks are allocated to the file in such a way that all of the file's logical blocks are assigned to the same physical block on the memory.
For contiguous allocation,
we have 100 blocks, in contiguous allocation first, we push the 100th block to 101 th block (we need two access), then we push the 99 th block to the 100 th block (we need two access again) and so on up to 51 th block. Now, 51 block is empty, then we push new block to 51 position list need one access).
So, Total access are= 50 read operations+ 50 write operations+1 operation to write the newly inserted block.
Total access are=101 operations (nA)
Contiguous allocation occurs when the blocks are allocated to the file in such a way that all of the file's logical blocks are assigned to the same physical block on the memory.
For contiguous allocation,
we have 100 blocks, in contiguous allocation first, we push the 100th block to 101 th block (we need two access), then we push the 99 th block to the 100 th block (we need two access again) and so on up to 51 th block. Now, 51 block is empty, then we push new block to 51 position list need one access).
So, Total access are= 50 read operations+ 50 write operations+1 operation to write the newly inserted block.
Total access are=101 operations (nA)
Linked allocation:
In this scheme, each file is a linked list of disc blocks that do not have to be contiguous. Disk blocks can be placed anywhere on the disc. The directory entry includes a reference to the beginning and end of the file block. Each block carries a reference to the next block occupied by the file.
In this scheme, each file is a linked list of disc blocks that do not have to be contiguous. Disk blocks can be placed anywhere on the disc. The directory entry includes a reference to the beginning and end of the file block. Each block carries a reference to the next block occupied by the file.
For linked allocation,
we need to access the block from 1 to 50, new block access that should insert between 50 and 51 blocks, and access 51 blocks. So, the total access is 52.
we need to access the block from 1 to 50, new block access that should insert between 50 and 51 blocks, and access 51 blocks. So, the total access is 52.
Total access are= 50 read operations+ 1 operation delete next pointer of 50 th element +1 operation to connect it to the 51 th element.
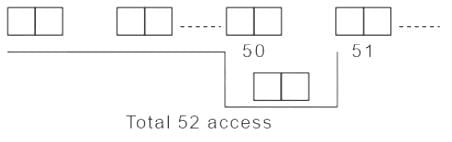
Total access are=52 operations (nB)
Total operations are required= nA+ nB
Total operations are required= 101+52
Total operations are required= 153.
Hence the correct answer is 153.
Total operations are required= nA+ nB
Total operations are required= 101+52
Total operations are required= 153.
Hence the correct answer is 153.
There are 200 tracks on a disk platter and the pending requests have come in the order - 36, 69, 167, 76, 42, 51, 126, 12, and 199, Assume the arm is located at the 100th track and moving towards track 200. If the sequence of disc access is 126, 167, 199, 12, 36, 42, 51, 69, and 76 then which disc access scheduling policy is used?- a)Elevator
- b)Shorter Seek time First
- c)C-SCAN
- d)First Come First Served
Correct answer is option 'C'. Can you explain this answer?
There are 200 tracks on a disk platter and the pending requests have come in the order - 36, 69, 167, 76, 42, 51, 126, 12, and 199, Assume the arm is located at the 100th track and moving towards track 200. If the sequence of disc access is 126, 167, 199, 12, 36, 42, 51, 69, and 76 then which disc access scheduling policy is used?
a)
Elevator
b)
Shorter Seek time First
c)
C-SCAN
d)
First Come First Served
|
|
Luminary Institute answered |
Option 1:
The elevator algorithm is also known as the SCAN algorithm.
The elevator algorithm is also known as the SCAN algorithm.
In this algorithm, the disk moves in a particular direction servicing the requests coming in the way till the end & reverse the direction & service all the requests.
Option 2:
In Shortest Seek Time First(SSTF), the algorithm selects disk I/O which requires the least disk arm movement from the current position
In Shortest Seek Time First(SSTF), the algorithm selects disk I/O which requires the least disk arm movement from the current position
Option 3:
In C-scan i.e. Circular Elevator, the disk moves in a particular direction servicing the requests coming in the way till the end & reverse the direction & again goes to the start point & starts servicing the requests once reach the start point.
In C-scan i.e. Circular Elevator, the disk moves in a particular direction servicing the requests coming in the way till the end & reverse the direction & again goes to the start point & starts servicing the requests once reach the start point.
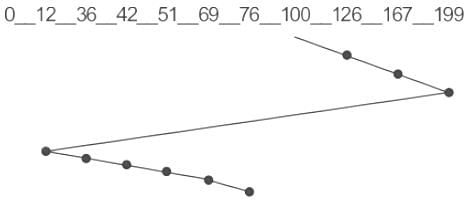
Option 4:
In First Come First Serve(FCFS), the disk service the request that comes first.
Hence, the correct answer is "option 3".
In First Come First Serve(FCFS), the disk service the request that comes first.
Hence, the correct answer is "option 3".
Suppose that the rotating disk head is moving with 200 tracks numbered from 0 to 199 and is currently serving a request at track 65. Disk queue requests are as follows: 93, 173, 132, 20, 35, 150, 100, 175 and 55.Which of the following statements satisfies these requests for the SSTF (Shortest Seek Time First) algorithm?- a)Total head movements = 250 cylinders
- b)Total head movements = 200 cylinders
- c)The request order is 65, 55, 35, 20, 93, 100, 132, 150, 173 and, 175
- d)The request order is 65, 55, 93, 173, 132, 20, 35, 150, 100, and 175
Correct answer is option 'B,C'. Can you explain this answer?
Suppose that the rotating disk head is moving with 200 tracks numbered from 0 to 199 and is currently serving a request at track 65. Disk queue requests are as follows: 93, 173, 132, 20, 35, 150, 100, 175 and 55.Which of the following statements satisfies these requests for the SSTF (Shortest Seek Time First) algorithm?
a)
Total head movements = 250 cylinders
b)
Total head movements = 200 cylinders
c)
The request order is 65, 55, 35, 20, 93, 100, 132, 150, 173 and, 175
d)
The request order is 65, 55, 93, 173, 132, 20, 35, 150, 100, and 175
|
|
Sudhir Patel answered |
Given disk queue requests 93, 173, 132, 20, 35, 150, 100, 175, 55
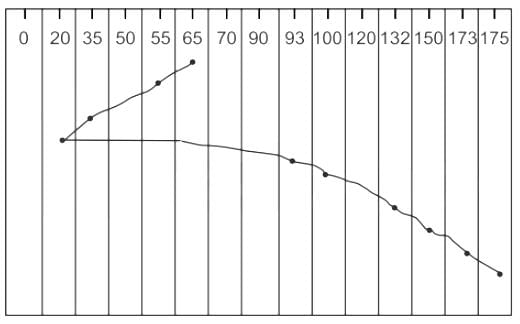
Total head movements = 10 + 20 + 15 + 73 + 7 + 32 + 18 + 23 + 2
Total head movements = 200 cylinders
Hence the correct answer is option 2 and option 3.
Total head movements = 200 cylinders
Hence the correct answer is option 2 and option 3.
Consider a disk system having 60 cylinders. Disk requests are received by a disk drive for cylinders 10, 22, 20, 2, 40, 6, and 38, in that order. Assuming the disk head is currently at cylinder 20, what is the time taken to satisfy all the requests if it takes 2 milliseconds to move from one cylinder to an adjacent one and Shortest Seek Time First (SSTF) algorithm is used ?- a)240 milliseconds
- b)96 milliseconds
- c)120 milliseconds
- d)112 milliseconds
Correct answer is option 'C'. Can you explain this answer?
Consider a disk system having 60 cylinders. Disk requests are received by a disk drive for cylinders 10, 22, 20, 2, 40, 6, and 38, in that order. Assuming the disk head is currently at cylinder 20, what is the time taken to satisfy all the requests if it takes 2 milliseconds to move from one cylinder to an adjacent one and Shortest Seek Time First (SSTF) algorithm is used ?
a)
240 milliseconds
b)
96 milliseconds
c)
120 milliseconds
d)
112 milliseconds
|
|
Sudhir Patel answered |
Shortest Seek Time First (SSTF)
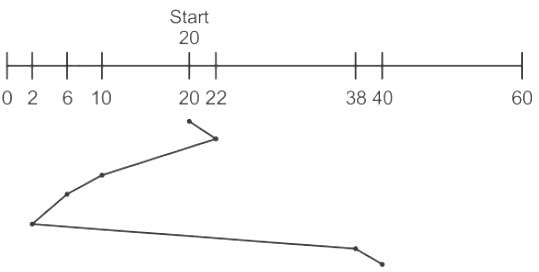
SSTF =(22-20+22-10+10-6+6-2+38-2+40-38)
=2+12+4+4+36+2
=60
=2+12+4+4+36+2
=60
It takes 2 milliseconds to move from one cylinder to adjacent one = 60x2 =120 milliseconds
∴ Hence the correct answer is 120 milliseconds.
∴ Hence the correct answer is 120 milliseconds.
Suppose a disk has 201 cylinders, numbered from 0 to 200. At some time the disk arm is at cylinder 100, and there is a queue of disk access requests for cylinders 30, 85, 90, 100, 105, 110, 135 and 145. If Shortest-Seek Time First (SSTF) is being used for scheduling the disk access, the request for cylinder 90 is serviced after servicing ____________ number of requests.- a)1
- b)2
- c)3
- d)4
Correct answer is option 'C'. Can you explain this answer?
Suppose a disk has 201 cylinders, numbered from 0 to 200. At some time the disk arm is at cylinder 100, and there is a queue of disk access requests for cylinders 30, 85, 90, 100, 105, 110, 135 and 145. If Shortest-Seek Time First (SSTF) is being used for scheduling the disk access, the request for cylinder 90 is serviced after servicing ____________ number of requests.
a)
1
b)
2
c)
3
d)
4
|
|
Sanya Agarwal answered |
In Shortest-Seek-First algorithm, request closest to the current position of the disk arm and head is handled first. In this question, the arm is currently at cylinder number 100. Now the requests come in the queue order for cylinder numbers 30, 85, 90, 100, 105, 110, 135 and 145. The disk will service that request first whose cylinder number is closest to its arm. Hence 1st serviced request is for cylinder no 100 ( as the arm is itself pointing to it ), then 105, then 110, and then the arm comes to service request for cylinder 90. Hence before servicing request for cylinder 90, the disk would had serviced 3 requests. Hence option C.
Determine the number of page faults when references to pages occur in the order -1, 2,4, 5, 2,1,2, 4. Assume that the main memory can accommodate 3 pages and the main memory already has the pages 1 and 2, with page 1 having been brought earlier than page 2. (Assume LRU algorithm is used)- a)3
- b)5
- c)4
- d)None of the above
Correct answer is option 'C'. Can you explain this answer?
Determine the number of page faults when references to pages occur in the order -1, 2,4, 5, 2,1,2, 4. Assume that the main memory can accommodate 3 pages and the main memory already has the pages 1 and 2, with page 1 having been brought earlier than page 2. (Assume LRU algorithm is used)
a)
3
b)
5
c)
4
d)
None of the above
|
|
Aditya Nair answered |
1, 2, 4, 5, 2, 1 , 2 , 4
Since 1 and 2 are already in the memory which can accomodate 3 pages

Since 1 and 2 are already in the memory which can accomodate 3 pages
The address sequence generated by tracing a particular program executing in a pure demand paging system with 100 records per page, with 1 free main memory frame is recorded as follows. What is the number of page faults?
0100, 0200, 0430, 0499, 0510, 0530, 0560, 0120, 0220, 0240, 0260, 0320, 0370 - a)13
- b)8
- c)7
- d)10
Correct answer is option 'C'. Can you explain this answer?
The address sequence generated by tracing a particular program executing in a pure demand paging system with 100 records per page, with 1 free main memory frame is recorded as follows. What is the number of page faults?
0100, 0200, 0430, 0499, 0510, 0530, 0560, 0120, 0220, 0240, 0260, 0320, 0370
0100, 0200, 0430, 0499, 0510, 0530, 0560, 0120, 0220, 0240, 0260, 0320, 0370
a)
13
b)
8
c)
7
d)
10
|
|
Sonal Nair answered |
When it tries to access 0100, it results in a page fault as the memory is empty right now. So, it loads the second page (which has the addresses 100 - 199). Trying to access 200 will result in a page fault, as it is not in memory right now. So the third page with the addresses from 200 to 299 will replace the second page in memory. Trying to access 430 will result in another page fault. Proceeding this way, we find trying to access the addresses 0510,0120,0220 and 0320 will all result in page faults. So, altogether 7 page faults.
Disk scheduling involves deciding- a)Which disk should be accessed next
- b)The order in which disk access requests must be serviced
- c)The physical location where files should be accessed in the disk
- d)None of the above
Correct answer is option 'B'. Can you explain this answer?
Disk scheduling involves deciding
a)
Which disk should be accessed next
b)
The order in which disk access requests must be serviced
c)
The physical location where files should be accessed in the disk
d)
None of the above
|
|
Samarth Ghosh answered |
Disk scheduling manages the disk access and order of request to be fulfilled. It does not have the bounds in determining the physical location, where actually the files are stored.
Which of the following is dense index- a)Primary index
- b)Clusters index
- c)Secondary index
- d)Primary non key index
Correct answer is option 'C'. Can you explain this answer?
Which of the following is dense index
a)
Primary index
b)
Clusters index
c)
Secondary index
d)
Primary non key index
|
|
Sudhir Patel answered |
Indexing
Indexing is a way to optimize the performance of a database by minimizing the number of disk accesses required when a query is processed.
It is a data structure technique that is used to quickly locate and access the data in a database
There are the following type of Indexes
Indexing is a way to optimize the performance of a database by minimizing the number of disk accesses required when a query is processed.
It is a data structure technique that is used to quickly locate and access the data in a database
There are the following type of Indexes
Primary index
It is maintained for the anchor value of block i,e one key-value per block maintained in Index file.
It is maintained for the anchor value of block i,e one key-value per block maintained in Index file.
Clustering index
It is basically a mixed sort of Indexing i,e Dense as it is maintained for unique value (key) and Sparse as it is not maintained for every value.
It is basically a mixed sort of Indexing i,e Dense as it is maintained for unique value (key) and Sparse as it is not maintained for every value.
Match the following.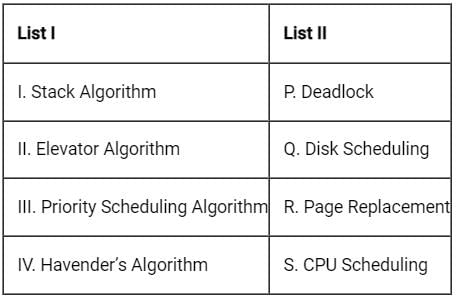
- a)I – R, II – Q, III – S, IV – P
- b)I – Q, II – R, III –S, IV – P
- c)I – R, II – Q, III – P, IV – S
- d)I – Q, II – R, III – P, IV – S
Correct answer is option 'A'. Can you explain this answer?
Match the following.
a)
I – R, II – Q, III – S, IV – P
b)
I – Q, II – R, III –S, IV – P
c)
I – R, II – Q, III – P, IV – S
d)
I – Q, II – R, III – P, IV – S
|
|
Luminary Institute answered |
Stack algorithm:
A page replacement algorithm is said to satisfy the inclusion property, or it is called as stack algorithm if the set of pages in a k frame memory is always a subset of the pages in a k+1 frame memory.
A page replacement algorithm is said to satisfy the inclusion property, or it is called as stack algorithm if the set of pages in a k frame memory is always a subset of the pages in a k+1 frame memory.
Elevator algorithm:
It is a disk scheduling algorithm, also known as scan algorithm in which head, starts from one end of disk and moves towards other end by servicing each request in between and reach other end.
It is a disk scheduling algorithm, also known as scan algorithm in which head, starts from one end of disk and moves towards other end by servicing each request in between and reach other end.
Priority scheduling algorithm:
It is a CPU scheduling algorithm in which each process is assigned a priority and processes according to their priority.
It is a CPU scheduling algorithm in which each process is assigned a priority and processes according to their priority.
Havender’s Algorithm:
It is related with deadlock. In this, all the resources required by process will be requested at once.
It is related with deadlock. In this, all the resources required by process will be requested at once.
There are 200 tracks on a disc platter and the pending requests have come in the order - 36, 69, 167, 76, 42, 51, 126, 12 and 199. Assume the arm is located at the 100 track and moving towards track 199. If sequence of disc access is 126, 167, 199, 12, 36, 42, 51, 69 and 76 then which disc access scheduling policy is used?- a)Elevator
- b)Shortest seek-time first
- c)C-SCAN
- d)First Come First Served
Correct answer is option 'C'. Can you explain this answer?
There are 200 tracks on a disc platter and the pending requests have come in the order - 36, 69, 167, 76, 42, 51, 126, 12 and 199. Assume the arm is located at the 100 track and moving towards track 199. If sequence of disc access is 126, 167, 199, 12, 36, 42, 51, 69 and 76 then which disc access scheduling policy is used?
a)
Elevator
b)
Shortest seek-time first
c)
C-SCAN
d)
First Come First Served
|
|
Nandini Khanna answered |
The disc access scheduling policy used is C-SCAN.
Explanation:
The C-SCAN (Circular SCAN) algorithm is a disk scheduling algorithm that works by moving the disk arm only in one direction and servicing the requests in a circular manner. When the arm reaches the end of the disk, it wraps around to the beginning and continues servicing requests in the same direction.
Given that the arm is initially located at track 100 and moving towards track 199, let's analyze the sequence of disc access to determine the scheduling policy used:
1. 126: The arm moves from track 100 towards track 199, passing through tracks 126 and 167, and finally reaches track 199.
2. 167: Since the arm is already at track 199, it does not need to move. The request is serviced.
3. 199: Same as the previous step, the arm does not need to move and the request is serviced.
4. 12: The arm has reached the end of the disk and wraps around to the beginning. It moves from track 0 to track 12 to service the request.
5. 36: The arm continues moving in the same direction from track 12 to track 36.
6. 42: The arm moves from track 36 to track 42.
7. 51: The arm moves from track 42 to track 51.
8. 69: The arm moves from track 51 to track 69.
9. 76: The arm moves from track 69 to track 76.
Conclusion:
As we can see, the sequence of disc access follows the circular pattern of the C-SCAN algorithm. The arm moves in one direction, servicing the requests in a circular manner, and wraps around to the beginning when it reaches the end of the disk. Therefore, the disc access scheduling policy used is C-SCAN.
Explanation:
The C-SCAN (Circular SCAN) algorithm is a disk scheduling algorithm that works by moving the disk arm only in one direction and servicing the requests in a circular manner. When the arm reaches the end of the disk, it wraps around to the beginning and continues servicing requests in the same direction.
Given that the arm is initially located at track 100 and moving towards track 199, let's analyze the sequence of disc access to determine the scheduling policy used:
1. 126: The arm moves from track 100 towards track 199, passing through tracks 126 and 167, and finally reaches track 199.
2. 167: Since the arm is already at track 199, it does not need to move. The request is serviced.
3. 199: Same as the previous step, the arm does not need to move and the request is serviced.
4. 12: The arm has reached the end of the disk and wraps around to the beginning. It moves from track 0 to track 12 to service the request.
5. 36: The arm continues moving in the same direction from track 12 to track 36.
6. 42: The arm moves from track 36 to track 42.
7. 51: The arm moves from track 42 to track 51.
8. 69: The arm moves from track 51 to track 69.
9. 76: The arm moves from track 69 to track 76.
Conclusion:
As we can see, the sequence of disc access follows the circular pattern of the C-SCAN algorithm. The arm moves in one direction, servicing the requests in a circular manner, and wraps around to the beginning when it reaches the end of the disk. Therefore, the disc access scheduling policy used is C-SCAN.
Put the following disk scheduling policies results in minimum amount of head movement.- a)FCFS
- b)Circular SCAN
- c)Elevator
Correct answer is option 'C'. Can you explain this answer?
Put the following disk scheduling policies results in minimum amount of head movement.
a)
FCFS
b)
Circular SCAN
c)
Elevator
|
|
Sanya Agarwal answered |
Circular scanning works just like the elevator to some extent. It begins its scan toward the nearest end and works its way all the way to the end of the system. Once it hits the bottom or top it jumps to the other end and moves in the same direction. Circular SCAN has more head movement than SCAN (elevator) because Circular SCAN has circular jump and it does count as a head movement. SCAN (elevator) is the best choice here.
Thrashing- a)Reduces page I/O
- b)Decreases the degree of multiprogramming
- c)Implies excessive page I/O
- d)Improves the system performance
Correct answer is option 'C'. Can you explain this answer?
Thrashing
a)
Reduces page I/O
b)
Decreases the degree of multiprogramming
c)
Implies excessive page I/O
d)
Improves the system performance
|
|
Rohan Shah answered |
When to increase multi-programming, a lot of processes are brought into memory. Then, what happens is, no process gets enough memory space and processor needs to keep bringing new pages into the memory to satisfy the requests. (A lot of page faults occurs). This process of excessive page replacements is called thrashing, which in turn reduces the overall performance.
There are five virtual pages, numbered from 0 to 4. The page are referenced in the following order
0 1 2 3 0 1 4 0 1 2 3 4
If FIFO page replacement algorithm is used then find:
1. Number of page replacement faults that occur if 3 page frames are present.
2. Number of page faults that occur if 4 page frames are present.- a)10,9
- b)9,10
- c)9, 8
- d)10,11
Correct answer is option 'B'. Can you explain this answer?
There are five virtual pages, numbered from 0 to 4. The page are referenced in the following order
0 1 2 3 0 1 4 0 1 2 3 4
If FIFO page replacement algorithm is used then find:
1. Number of page replacement faults that occur if 3 page frames are present.
2. Number of page faults that occur if 4 page frames are present.
0 1 2 3 0 1 4 0 1 2 3 4
If FIFO page replacement algorithm is used then find:
1. Number of page replacement faults that occur if 3 page frames are present.
2. Number of page faults that occur if 4 page frames are present.
a)
10,9
b)
9,10
c)
9, 8
d)
10,11
|
|
Vaibhav Banerjee answered |
If 3 page frames are used
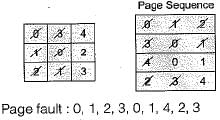
Page hit : 0, 1, 4.
∴ Number of page fault = 9
If 4 pages frames are used
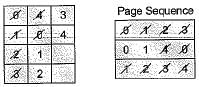
Page faults ; 0, 1, 2, 3, 4, 0, 1,2, 3, 4 Page hit : 0, 1
∴ Number of page faults = 10
Page hit : 0, 1, 4.
∴ Number of page fault = 9
If 4 pages frames are used
Page faults ; 0, 1, 2, 3, 4, 0, 1,2, 3, 4 Page hit : 0, 1
∴ Number of page faults = 10
For a magnetic disk with concentric circular tracks, the seek latency is not linearly proportional to the seek distance due to- a)non-uniform distribution of requests
- b)arm starting and stopping inertia
- c)higher capacity of tracks on the periphery of the platter
- d)use of unfair arm scheduling policies
Correct answer is option 'B'. Can you explain this answer?
For a magnetic disk with concentric circular tracks, the seek latency is not linearly proportional to the seek distance due to
a)
non-uniform distribution of requests
b)
arm starting and stopping inertia
c)
higher capacity of tracks on the periphery of the platter
d)
use of unfair arm scheduling policies
|
|
Ravi Singh answered |
Whenever head moves from one track to other then its speed and direction changes, which is noting but change in motion or the case of inertia. So answer B
Consider an operating system capable of loading and executing a single sequential user process at a time. The disk head scheduling algorithm used is First Come First Served (FCFS). If FCFS is replaced by Shortest Seek Time First (SSTF), claimed by the vendor to give 50% better benchmark results, what is the expected improvement in the I/O performance of user programs?- a)50%
- b)40%
- c)25%
- d)0%
Correct answer is option 'D'. Can you explain this answer?
Consider an operating system capable of loading and executing a single sequential user process at a time. The disk head scheduling algorithm used is First Come First Served (FCFS). If FCFS is replaced by Shortest Seek Time First (SSTF), claimed by the vendor to give 50% better benchmark results, what is the expected improvement in the I/O performance of user programs?
a)
50%
b)
40%
c)
25%
d)
0%
|
|
Sanya Agarwal answered |
Since Operating System can execute a single sequential user process at a time, the disk is accessed in FCFS manner always. The OS never has a choice to pick an IO from multiple IOs as there is always one IO at a time
Disk requests are received by a disk drive for cylinder 5, 25, 18, 3, 39, 8 and 35 in that order. A seek takes 5 msec per cylinder moved. How much seek time is needed to serve these requests for a Shortest Seek First (SSF) algorithm? Assume that the arm is at cylinder 20 when the last of these requests is made with none of the requests yet served- a)125 msec
- b)295 msec
- c)575 msec
- d)750 msec
Correct answer is option 'B'. Can you explain this answer?
Disk requests are received by a disk drive for cylinder 5, 25, 18, 3, 39, 8 and 35 in that order. A seek takes 5 msec per cylinder moved. How much seek time is needed to serve these requests for a Shortest Seek First (SSF) algorithm? Assume that the arm is at cylinder 20 when the last of these requests is made with none of the requests yet served
a)
125 msec
b)
295 msec
c)
575 msec
d)
750 msec
|
|
Dhruba Goyal answered |
Shortest Seek First (SSF) Algorithm
The Shortest Seek First (SSF) algorithm aims to minimize the seek time by serving the disk requests in the order of their closest proximity to the current position of the disk arm.
Given Information:
- Disk requests: 5, 25, 18, 3, 39, 8, 35
- Initial position of the disk arm: 20
- Seek time per cylinder moved: 5 msec
Calculating Seek Time for SSF Algorithm:
1. Calculate the seek time for each request based on the SSF algorithm:
- Calculate the absolute difference between the current position of the disk arm and each request.
- Sort the requests in ascending order of their absolute differences.
Sorted requests based on absolute differences:
18, 25, 8, 35, 5, 39, 3
2. Calculate the seek time for each request by multiplying its absolute difference by the seek time per cylinder moved:
- Seek time for request 18: 5 * (18 - 20) = -10 msec (Negative value indicates movement in the opposite direction)
- Seek time for request 25: 5 * (25 - 20) = 25 msec
- Seek time for request 8: 5 * (8 - 20) = -60 msec
- Seek time for request 35: 5 * (35 - 20) = 75 msec
- Seek time for request 5: 5 * (5 - 20) = -75 msec
- Seek time for request 39: 5 * (39 - 20) = 95 msec
- Seek time for request 3: 5 * (3 - 20) = -85 msec
3. Calculate the total seek time by summing up the seek times of all requests:
Total Seek Time = -10 + 25 - 60 + 75 - 75 + 95 - 85 = -25 msec
Explanation:
The negative and positive seek times indicate the direction in which the disk arm needs to move. A negative value means it needs to move towards lower cylinder numbers, while a positive value means it needs to move towards higher cylinder numbers.
In this case, the total seek time is -25 msec, indicating that the disk arm needs to move towards lower cylinder numbers. The absolute value of the seek time (-25) represents the total distance the disk arm needs to travel in terms of cylinders.
Final Answer:
Therefore, the seek time needed to serve the given requests using the Shortest Seek First (SSF) algorithm is 25 msec. Hence, option B is the correct answer.
The Shortest Seek First (SSF) algorithm aims to minimize the seek time by serving the disk requests in the order of their closest proximity to the current position of the disk arm.
Given Information:
- Disk requests: 5, 25, 18, 3, 39, 8, 35
- Initial position of the disk arm: 20
- Seek time per cylinder moved: 5 msec
Calculating Seek Time for SSF Algorithm:
1. Calculate the seek time for each request based on the SSF algorithm:
- Calculate the absolute difference between the current position of the disk arm and each request.
- Sort the requests in ascending order of their absolute differences.
Sorted requests based on absolute differences:
18, 25, 8, 35, 5, 39, 3
2. Calculate the seek time for each request by multiplying its absolute difference by the seek time per cylinder moved:
- Seek time for request 18: 5 * (18 - 20) = -10 msec (Negative value indicates movement in the opposite direction)
- Seek time for request 25: 5 * (25 - 20) = 25 msec
- Seek time for request 8: 5 * (8 - 20) = -60 msec
- Seek time for request 35: 5 * (35 - 20) = 75 msec
- Seek time for request 5: 5 * (5 - 20) = -75 msec
- Seek time for request 39: 5 * (39 - 20) = 95 msec
- Seek time for request 3: 5 * (3 - 20) = -85 msec
3. Calculate the total seek time by summing up the seek times of all requests:
Total Seek Time = -10 + 25 - 60 + 75 - 75 + 95 - 85 = -25 msec
Explanation:
The negative and positive seek times indicate the direction in which the disk arm needs to move. A negative value means it needs to move towards lower cylinder numbers, while a positive value means it needs to move towards higher cylinder numbers.
In this case, the total seek time is -25 msec, indicating that the disk arm needs to move towards lower cylinder numbers. The absolute value of the seek time (-25) represents the total distance the disk arm needs to travel in terms of cylinders.
Final Answer:
Therefore, the seek time needed to serve the given requests using the Shortest Seek First (SSF) algorithm is 25 msec. Hence, option B is the correct answer.
A certain moving arm disk storage with one head has following specifications:
Number of tracks/recording surface = 200
Disk rotation speed = 2400 rpm
Track storage capacity = 62500 bits
The average latency time (assume that the head can move from one track to another only by traversing the entire track) is- a)2.5 s
- b)2.9 s
- c)3.1 s
- d)3.6 s
Correct answer is option 'A'. Can you explain this answer?
A certain moving arm disk storage with one head has following specifications:
Number of tracks/recording surface = 200
Disk rotation speed = 2400 rpm
Track storage capacity = 62500 bits
The average latency time (assume that the head can move from one track to another only by traversing the entire track) is
Number of tracks/recording surface = 200
Disk rotation speed = 2400 rpm
Track storage capacity = 62500 bits
The average latency time (assume that the head can move from one track to another only by traversing the entire track) is
a)
2.5 s
b)
2.9 s
c)
3.1 s
d)
3.6 s
|
|
Pranav Patel answered |
To cover 2400 x 62500 bits, 60 s are needed. Average latency time is the time needed to traverse 100 tracks i.e. 100 x 62500 bits, which is 2.5 s.
Which of the following page replacement algorithms suffers from Belady’s anomaly?- a)Shortest job first
- b)Round robin
- c)First-come-first-serve
- d)Elevator
Correct answer is option 'C'. Can you explain this answer?
Which of the following page replacement algorithms suffers from Belady’s anomaly?
a)
Shortest job first
b)
Round robin
c)
First-come-first-serve
d)
Elevator
|
|
Nabanita Basak answered |
There are two types of page replacement algorithm mainly stack based and non-stack based, it is observed that algorithms which follows the latter one suffers from Belady’s anomaly. FIFO suffers from Belady's anomaly.
Consider the following five disk five disk access requests of the form (request id, cylinder number) that are present in the disk scheduler queue at a given time.(P, 155), (Q, 85), (R, 110), (S, 30), (T, 115)Assume the head is positioned at cylinder 100. The scheduler follows Shortest Seek Time First scheduling to service the requests. Which one of the following statements is FALSE ?- a)T is serviced before P
- b)Q is serviced after S, but before T
- c)The head reverses its direction of movement between servicing of Q and P
- d)R is serviced before P
Correct answer is option 'B'. Can you explain this answer?
Consider the following five disk five disk access requests of the form (request id, cylinder number) that are present in the disk scheduler queue at a given time.
(P, 155), (Q, 85), (R, 110), (S, 30), (T, 115)
Assume the head is positioned at cylinder 100. The scheduler follows Shortest Seek Time First scheduling to service the requests. Which one of the following statements is FALSE ?
a)
T is serviced before P
b)
Q is serviced after S, but before T
c)
The head reverses its direction of movement between servicing of Q and P
d)
R is serviced before P
|
|
Madhurima Mukherjee answered |
Shortest Seek Time First (SSTF) Scheduling
SSTF is a disk scheduling algorithm that selects the disk request with the shortest seek time from the current head position. The seek time is the time taken by the disk arm to move from its current position to the requested cylinder.
Given Information:
- Disk access requests: (P, 155), (Q, 85), (R, 110), (S, 30), (T, 115)
- Current head position: Cylinder 100
Step 1: Calculating Seek Time
- Calculate the seek time for each request by finding the absolute difference between the current head position and the requested cylinder number.
- Seek Time for each request:
- P: |155 - 100| = 55
- Q: |85 - 100| = 15
- R: |110 - 100| = 10
- S: |30 - 100| = 70
- T: |115 - 100| = 15
Step 2: Servicing Requests
- The disk scheduler services the request with the shortest seek time first.
- Initially, the head is at cylinder 100.
- The request with the shortest seek time is R with a seek time of 10.
- The head moves to cylinder 110.
Step 3: Updating Seek Time
- Recalculate the seek time for each request based on the new head position.
- Seek Time for each request:
- P: |155 - 110| = 45
- Q: |85 - 110| = 25
- S: |30 - 110| = 80
- T: |115 - 110| = 5
Step 4: Servicing Requests
- The request with the shortest seek time is T with a seek time of 5.
- The head moves to cylinder 115.
Step 5: Updating Seek Time
- Recalculate the seek time for each request based on the new head position.
- Seek Time for each request:
- P: |155 - 115| = 40
- Q: |85 - 115| = 30
- S: |30 - 115| = 85
Step 6: Servicing Requests
- The request with the shortest seek time is Q with a seek time of 30.
- The head moves to cylinder 85.
Step 7: Updating Seek Time
- Recalculate the seek time for each request based on the new head position.
- Seek Time for each request:
- P: |155 - 85| = 70
- S: |30 - 85| = 55
Step 8: Servicing Requests
- The request with the shortest seek time is S with a seek time of 55.
- The head moves to cylinder 30.
Step 9: Updating Seek Time
- Recalculate the seek time for the remaining request based on the new head position.
- Seek Time for the remaining request:
- P: |155 - 30| = 125
Step
SSTF is a disk scheduling algorithm that selects the disk request with the shortest seek time from the current head position. The seek time is the time taken by the disk arm to move from its current position to the requested cylinder.
Given Information:
- Disk access requests: (P, 155), (Q, 85), (R, 110), (S, 30), (T, 115)
- Current head position: Cylinder 100
Step 1: Calculating Seek Time
- Calculate the seek time for each request by finding the absolute difference between the current head position and the requested cylinder number.
- Seek Time for each request:
- P: |155 - 100| = 55
- Q: |85 - 100| = 15
- R: |110 - 100| = 10
- S: |30 - 100| = 70
- T: |115 - 100| = 15
Step 2: Servicing Requests
- The disk scheduler services the request with the shortest seek time first.
- Initially, the head is at cylinder 100.
- The request with the shortest seek time is R with a seek time of 10.
- The head moves to cylinder 110.
Step 3: Updating Seek Time
- Recalculate the seek time for each request based on the new head position.
- Seek Time for each request:
- P: |155 - 110| = 45
- Q: |85 - 110| = 25
- S: |30 - 110| = 80
- T: |115 - 110| = 5
Step 4: Servicing Requests
- The request with the shortest seek time is T with a seek time of 5.
- The head moves to cylinder 115.
Step 5: Updating Seek Time
- Recalculate the seek time for each request based on the new head position.
- Seek Time for each request:
- P: |155 - 115| = 40
- Q: |85 - 115| = 30
- S: |30 - 115| = 85
Step 6: Servicing Requests
- The request with the shortest seek time is Q with a seek time of 30.
- The head moves to cylinder 85.
Step 7: Updating Seek Time
- Recalculate the seek time for each request based on the new head position.
- Seek Time for each request:
- P: |155 - 85| = 70
- S: |30 - 85| = 55
Step 8: Servicing Requests
- The request with the shortest seek time is S with a seek time of 55.
- The head moves to cylinder 30.
Step 9: Updating Seek Time
- Recalculate the seek time for the remaining request based on the new head position.
- Seek Time for the remaining request:
- P: |155 - 30| = 125
Step
The total time to prepare a disk drive mechanism for a block of data to be read from it is- a)seek time
- b)latency
- c)latency plus seek time
- d)transmission time
Correct answer is option 'C'. Can you explain this answer?
The total time to prepare a disk drive mechanism for a block of data to be read from it is
a)
seek time
b)
latency
c)
latency plus seek time
d)
transmission time
|
|
Aravind Sengupta answered |
Explanation:
Latency:
- Latency is the time it takes for the desired data to rotate under the read/write head.
- It is dependent on the rotational speed of the disk, typically measured in milliseconds.
Seek Time:
- Seek time is the time it takes for the read/write head to move to the correct track on the disk.
- It is also measured in milliseconds.
Latency plus Seek Time:
- The total time to prepare a disk drive mechanism for a block of data to be read from it is the sum of latency and seek time.
- This is because the disk needs to rotate to the correct position and the read/write head needs to move to the correct track before the data can be accessed.
Transmission Time:
- Transmission time refers to the time it takes to actually transfer the data once the disk is ready.
Conclusion:
- Therefore, the total time to prepare a disk drive mechanism for a block of data to be read from it is the sum of latency and seek time.
In case of a DVD, the speed of data transfer is mentioned in multiples of?- a)150 KB/s
- b)1.38 MB/s
- c)300 KB/s
- d)2.40 MB/s
Correct answer is option 'B'. Can you explain this answer?
In case of a DVD, the speed of data transfer is mentioned in multiples of?
a)
150 KB/s
b)
1.38 MB/s
c)
300 KB/s
d)
2.40 MB/s
|
|
Shounak Sengupta answered |
Understanding DVD Data Transfer Speeds
Data transfer speed is crucial for understanding how quickly data can be read from or written to a DVD. The speed is often specified in multiples of a standard reference point.
DVD Speed Reference
- The standard speed reference for DVDs is based on the original CD speed, which is defined as 1x.
- For DVDs, 1x speed corresponds to a data transfer rate of 1.38 MB/s.
Options Analysis
- a) 150 KB/s: This is approximately 0.11x speed and does not represent a DVD standard.
- b) 1.38 MB/s: This is the correct answer as it represents the 1x speed for DVDs.
- c) 300 KB/s: This is approximately 0.22x speed, still not representative of DVD standards.
- d) 2.40 MB/s: This corresponds to approximately 1.74x speed, which is higher than the standard 1x speed.
Conclusion
- The correct answer is option 'B' because it accurately reflects the standard data transfer rate of a DVD at 1x speed, which is 1.38 MB/s. Understanding these speeds helps users evaluate the performance of DVD drives and the data transfer rates they can expect when using them.
Data transfer speed is crucial for understanding how quickly data can be read from or written to a DVD. The speed is often specified in multiples of a standard reference point.
DVD Speed Reference
- The standard speed reference for DVDs is based on the original CD speed, which is defined as 1x.
- For DVDs, 1x speed corresponds to a data transfer rate of 1.38 MB/s.
Options Analysis
- a) 150 KB/s: This is approximately 0.11x speed and does not represent a DVD standard.
- b) 1.38 MB/s: This is the correct answer as it represents the 1x speed for DVDs.
- c) 300 KB/s: This is approximately 0.22x speed, still not representative of DVD standards.
- d) 2.40 MB/s: This corresponds to approximately 1.74x speed, which is higher than the standard 1x speed.
Conclusion
- The correct answer is option 'B' because it accurately reflects the standard data transfer rate of a DVD at 1x speed, which is 1.38 MB/s. Understanding these speeds helps users evaluate the performance of DVD drives and the data transfer rates they can expect when using them.
Suppose there are six files F1, F2, F3, F4, F5, F6 with corresponding sizes 150 KB, 225 KB, 75 KB, 60 KB, 275 KB and 65 KB respectively. The files are to be stored on a sequential device in such a way that optimizes access time. In what order should the files be stored ?- a)F5, F2, F1, F3, F6, F4
- b)F4, F6, F3, F1, F2, F5
- c)F1, F2, F3, F4, F5, F6
- d)F6, F5, F4, F3, F2, F1
Correct answer is option 'B'. Can you explain this answer?
Suppose there are six files F1, F2, F3, F4, F5, F6 with corresponding sizes 150 KB, 225 KB, 75 KB, 60 KB, 275 KB and 65 KB respectively. The files are to be stored on a sequential device in such a way that optimizes access time. In what order should the files be stored ?
a)
F5, F2, F1, F3, F6, F4
b)
F4, F6, F3, F1, F2, F5
c)
F1, F2, F3, F4, F5, F6
d)
F6, F5, F4, F3, F2, F1
|
|
Rishabh Saha answered |
Explanation:
To optimize access time, the files should be stored in such a way that reduces seek time. Seek time is the time taken by the device to position the read/write head to the desired location on the storage medium.
Seek time is influenced by the following factors:
1. Distance: The distance the read/write head needs to move to access the file.
2. Order: The order in which the files are stored on the device.
To minimize seek time, we should arrange the files in increasing order of their sizes, as smaller files will require less movement of the read/write head.
Calculating the seek time for each option:
Let's calculate the seek time for each option and choose the one with the minimum seek time.
a) F5, F2, F1, F3, F6, F4:
Seek Time = Distance(F5, F2) + Distance(F2, F1) + Distance(F1, F3) + Distance(F3, F6) + Distance(F6, F4)
b) F4, F6, F3, F1, F2, F5:
Seek Time = Distance(F4, F6) + Distance(F6, F3) + Distance(F3, F1) + Distance(F1, F2) + Distance(F2, F5)
c) F1, F2, F3, F4, F5, F6:
Seek Time = Distance(F1, F2) + Distance(F2, F3) + Distance(F3, F4) + Distance(F4, F5) + Distance(F5, F6)
d) F6, F5, F4, F3, F2, F1:
Seek Time = Distance(F6, F5) + Distance(F5, F4) + Distance(F4, F3) + Distance(F3, F2) + Distance(F2, F1)
Calculating the seek time:
To calculate the seek time, we need to determine the distance between each pair of files. Assuming the read/write head starts at the first file and moves linearly to the subsequent files, the distance between two files can be calculated as the absolute difference between their sizes.
Seek Time for option a:
Distance(F5, F2) = |275 - 225| = 50
Distance(F2, F1) = |225 - 150| = 75
Distance(F1, F3) = |150 - 75| = 75
Distance(F3, F6) = |75 - 65| = 10
Distance(F6, F4) = |65 - 60| = 5
Seek Time (a) = 50 + 75 + 75 + 10 + 5 = 215
Seek Time for option b:
Distance(F4, F6) = |60 - 65| = 5
Distance(F6, F3) = |65 - 75| = 10
Distance(F3, F1) = |75 - 150| = 75
Distance(F1, F2) = |150 - 225| = 75
Distance(F2, F5) = |225 -
To optimize access time, the files should be stored in such a way that reduces seek time. Seek time is the time taken by the device to position the read/write head to the desired location on the storage medium.
Seek time is influenced by the following factors:
1. Distance: The distance the read/write head needs to move to access the file.
2. Order: The order in which the files are stored on the device.
To minimize seek time, we should arrange the files in increasing order of their sizes, as smaller files will require less movement of the read/write head.
Calculating the seek time for each option:
Let's calculate the seek time for each option and choose the one with the minimum seek time.
a) F5, F2, F1, F3, F6, F4:
Seek Time = Distance(F5, F2) + Distance(F2, F1) + Distance(F1, F3) + Distance(F3, F6) + Distance(F6, F4)
b) F4, F6, F3, F1, F2, F5:
Seek Time = Distance(F4, F6) + Distance(F6, F3) + Distance(F3, F1) + Distance(F1, F2) + Distance(F2, F5)
c) F1, F2, F3, F4, F5, F6:
Seek Time = Distance(F1, F2) + Distance(F2, F3) + Distance(F3, F4) + Distance(F4, F5) + Distance(F5, F6)
d) F6, F5, F4, F3, F2, F1:
Seek Time = Distance(F6, F5) + Distance(F5, F4) + Distance(F4, F3) + Distance(F3, F2) + Distance(F2, F1)
Calculating the seek time:
To calculate the seek time, we need to determine the distance between each pair of files. Assuming the read/write head starts at the first file and moves linearly to the subsequent files, the distance between two files can be calculated as the absolute difference between their sizes.
Seek Time for option a:
Distance(F5, F2) = |275 - 225| = 50
Distance(F2, F1) = |225 - 150| = 75
Distance(F1, F3) = |150 - 75| = 75
Distance(F3, F6) = |75 - 65| = 10
Distance(F6, F4) = |65 - 60| = 5
Seek Time (a) = 50 + 75 + 75 + 10 + 5 = 215
Seek Time for option b:
Distance(F4, F6) = |60 - 65| = 5
Distance(F6, F3) = |65 - 75| = 10
Distance(F3, F1) = |75 - 150| = 75
Distance(F1, F2) = |150 - 225| = 75
Distance(F2, F5) = |225 -
Which of the following is major part of time taken when accessing data on the disk?- a)Settle time
- b)Rotational latency
- c)Seek time
- d)Waiting time
Correct answer is option 'C'. Can you explain this answer?
Which of the following is major part of time taken when accessing data on the disk?
a)
Settle time
b)
Rotational latency
c)
Seek time
d)
Waiting time
|
|
Sanya Agarwal answered |
Seek time is time taken by the head to travel to the track of the disk where the data to be accessed is stored.

The address <400,16,29> corresponds to sector number:
- a)505035
- b)505036
- c)505037
- d)505038
Correct answer is option 'C'. Can you explain this answer?
The address <400,16,29> corresponds to sector number:
a)
505035
b)
505036
c)
505037
d)
505038
|
|
Sanya Agarwal answered |
The data on a disk is ordered in the following way. It is first stored on the first sector of the first surface of the first cylinder. Then in the next sector, and next, until all the sectors on the first track are exhausted. Then it moves on to the first sector of the second surface (remains at the same cylinder), then next sector and so on. It exhausts all available surfaces for the first cylinder in this way. After that, it moves on to repeat the process for the next cylinder

Special software to create a job queue is called a- a)Driver
- b)Spooler
- c)Interpreter
- d)Linkage editor
Correct answer is option 'B'. Can you explain this answer?
Special software to create a job queue is called a
a)
Driver
b)
Spooler
c)
Interpreter
d)
Linkage editor
|
|
Ayush Mukherjee answered |
Introduction:
Special software to create a job queue is called a spooler. A spooler is an important component of an operating system that manages the printing process by creating a job queue, allowing multiple users to send print jobs to a printer simultaneously.
Explanation:
A job queue is a list of print jobs that are waiting to be processed by a printer. When multiple users send print jobs to a printer, the spooler software collects these print jobs and organizes them in a queue based on their priority or the order in which they were received.
Benefits of Using a Spooler:
1. Print Job Management: The spooler software manages the print jobs efficiently, ensuring that each job is processed in the correct order and without any conflicts.
2. Multiple User Support: A spooler allows multiple users to send print jobs to a printer concurrently without causing delays or conflicts.
3. Background Printing: The spooler enables background printing, which means that users can continue working on other tasks while their print jobs are being processed in the background.
4. Error Handling: In case of printer errors or unavailability, the spooler can handle the situation by prioritizing other print jobs or notifying the user about the error.
Working of a Spooler:
1. Print Job Submission: When a user sends a print job, the spooler software captures the print data and stores it in a spool file.
2. Job Queue Creation: The spooler adds the print job to the job queue, maintaining the order of job submission.
3. Print Job Processing: The spooler sends the print jobs from the queue to the printer for processing. It manages the communication between the computer and the printer.
4. Job Completion: Once a print job is completed, the spooler removes it from the queue and notifies the user.
Conclusion:
In conclusion, a special software to create a job queue is called a spooler. It is an essential component of an operating system that manages the printing process by organizing print jobs in a queue, allowing multiple users to send print jobs to a printer simultaneously. The spooler ensures efficient print job management, background printing, error handling, and supports multiple users.
Special software to create a job queue is called a spooler. A spooler is an important component of an operating system that manages the printing process by creating a job queue, allowing multiple users to send print jobs to a printer simultaneously.
Explanation:
A job queue is a list of print jobs that are waiting to be processed by a printer. When multiple users send print jobs to a printer, the spooler software collects these print jobs and organizes them in a queue based on their priority or the order in which they were received.
Benefits of Using a Spooler:
1. Print Job Management: The spooler software manages the print jobs efficiently, ensuring that each job is processed in the correct order and without any conflicts.
2. Multiple User Support: A spooler allows multiple users to send print jobs to a printer concurrently without causing delays or conflicts.
3. Background Printing: The spooler enables background printing, which means that users can continue working on other tasks while their print jobs are being processed in the background.
4. Error Handling: In case of printer errors or unavailability, the spooler can handle the situation by prioritizing other print jobs or notifying the user about the error.
Working of a Spooler:
1. Print Job Submission: When a user sends a print job, the spooler software captures the print data and stores it in a spool file.
2. Job Queue Creation: The spooler adds the print job to the job queue, maintaining the order of job submission.
3. Print Job Processing: The spooler sends the print jobs from the queue to the printer for processing. It manages the communication between the computer and the printer.
4. Job Completion: Once a print job is completed, the spooler removes it from the queue and notifies the user.
Conclusion:
In conclusion, a special software to create a job queue is called a spooler. It is an essential component of an operating system that manages the printing process by organizing print jobs in a queue, allowing multiple users to send print jobs to a printer simultaneously. The spooler ensures efficient print job management, background printing, error handling, and supports multiple users.
A file system with 300 GByte disk uses a file descriptor with 8 direct block addresses, 1 indirect block address and 1 doubly indirect block address. The size of each disk block is 128 Bytes and the size of each disk block address is 8 Bytes. The maximum possible file size in this file system is- a)3 Kbytes
- b)35 Kbytes
- c)280 Bytes
- d)Dependent on the size of the disk
Correct answer is option 'B'. Can you explain this answer?
A file system with 300 GByte disk uses a file descriptor with 8 direct block addresses, 1 indirect block address and 1 doubly indirect block address. The size of each disk block is 128 Bytes and the size of each disk block address is 8 Bytes. The maximum possible file size in this file system is
a)
3 Kbytes
b)
35 Kbytes
c)
280 Bytes
d)
Dependent on the size of the disk
|
|
Sanya Agarwal answered |
Total number of possible addresses stored in a disk block = 128/8 = 16
Maximum number of addressable bytes due to direct address block = 8*128
Maximum number of addressable bytes due to 1 single indirect address block = 16*128
Maximum number of addressable bytes due to 1 double indirect address block = 16*16*128
Maximum number of addressable bytes due to 1 single indirect address block = 16*128
Maximum number of addressable bytes due to 1 double indirect address block = 16*16*128
The maximum possible file size = 8*128 + 16*128 + 16*16*128 = 35KB
In __________ disk scheduling algorithm, the disk head moves from one end to other end of the disk, serving the requests along the way. When the head reaches the other end, it immediately returns to the beginning of the disk without serving any requests on the return trip.- a)LOOK
- b)SCAN
- c)C-LOOK
- d)C-SCAN
Correct answer is option 'D'. Can you explain this answer?
In __________ disk scheduling algorithm, the disk head moves from one end to other end of the disk, serving the requests along the way. When the head reaches the other end, it immediately returns to the beginning of the disk without serving any requests on the return trip.
a)
LOOK
b)
SCAN
c)
C-LOOK
d)
C-SCAN
|
|
Sanya Agarwal answered |
In C-SCAN disk scheduling algorithm, the disk head serve the request from ine end to other end but when it reaches to other end it immediately returns to the starting of the disk without serving any request. Refer:Disk Scheduling Algorithms So option (D) is correct.
Given references to the following pages by a program
0, 9, 0, 1,8, 1,8, 7, 8, 7, 1,2, 8, 2, 7, 8, 2, 3, 8,3 How many page faults will occur if the program has been three page frames available to it and uses an optimal replacement?- a)7
- b)8
- c)9
- d)None of these
Correct answer is option 'A'. Can you explain this answer?
Given references to the following pages by a program
0, 9, 0, 1,8, 1,8, 7, 8, 7, 1,2, 8, 2, 7, 8, 2, 3, 8,3 How many page faults will occur if the program has been three page frames available to it and uses an optimal replacement?
0, 9, 0, 1,8, 1,8, 7, 8, 7, 1,2, 8, 2, 7, 8, 2, 3, 8,3 How many page faults will occur if the program has been three page frames available to it and uses an optimal replacement?
a)
7
b)
8
c)
9
d)
None of these
|
|
Soumya Dey answered |
Page sequence 0, 9, 0, 1,8, 1,8, 7, 8, 7, 1,2, 3, 2, 7, 8, 2, 3, 8, 3
Given 3 page frames are available and optimal replacement policy.

Given 3 page frames are available and optimal replacement policy.
What is compaction refers to- a)a technique for overcoming internal fragmentation
- b)a paging technique
- c)a technique for overcoming external fragmentation
- d)a technique for compressing the data
Correct answer is option 'C'. Can you explain this answer?
What is compaction refers to
a)
a technique for overcoming internal fragmentation
b)
a paging technique
c)
a technique for overcoming external fragmentation
d)
a technique for compressing the data
|
|
Krithika Gupta answered |
Compaction refers to a technique for overcoming external fragmentation in computer memory management. It involves rearranging the memory blocks to reduce or eliminate the fragmentation and make efficient use of available memory.
External fragmentation occurs when free memory is scattered throughout the memory space in small, non-contiguous blocks. This can happen due to the allocation and deallocation of variable-sized memory blocks. As a result, even though there may be enough free memory to satisfy a memory allocation request, it may not be available in a contiguous block, leading to inefficient memory utilization.
Compaction is a process of rearranging memory blocks to create larger contiguous blocks of free memory. It involves moving allocated blocks and adjusting memory addresses to eliminate the gaps between them. The goal is to create a single large block of free memory, which can then be used to satisfy larger memory allocation requests.
Here is a detailed explanation of how compaction works:
1. Identify fragmented memory: The first step is to identify the areas of memory that are fragmented and contain small free blocks.
2. Relocate allocated blocks: The next step is to move the allocated blocks towards one end of the memory space, typically towards the lower addresses. This involves updating memory addresses in the process control blocks (PCBs) and any pointers or references to the memory blocks.
3. Adjust memory addresses: After relocating the allocated blocks, the memory addresses need to be adjusted to reflect the new positions. This may involve updating pointers, references, and any other data structures that store memory addresses.
4. Create a large block of free memory: As the allocated blocks are moved, the gaps between them are eliminated, creating a larger contiguous block of free memory.
5. Update memory management data structures: Finally, the memory management data structures, such as the free block list or bitmap, need to be updated to reflect the changes in the memory layout.
By compacting the memory and eliminating external fragmentation, compaction improves memory utilization and reduces the likelihood of memory allocation failures due to insufficient contiguous free memory. However, compaction can be a costly operation in terms of time and computational resources, especially if there are many allocated blocks that need to be moved. Therefore, it is typically used in situations where external fragmentation becomes a significant problem and memory compaction can be performed efficiently.
External fragmentation occurs when free memory is scattered throughout the memory space in small, non-contiguous blocks. This can happen due to the allocation and deallocation of variable-sized memory blocks. As a result, even though there may be enough free memory to satisfy a memory allocation request, it may not be available in a contiguous block, leading to inefficient memory utilization.
Compaction is a process of rearranging memory blocks to create larger contiguous blocks of free memory. It involves moving allocated blocks and adjusting memory addresses to eliminate the gaps between them. The goal is to create a single large block of free memory, which can then be used to satisfy larger memory allocation requests.
Here is a detailed explanation of how compaction works:
1. Identify fragmented memory: The first step is to identify the areas of memory that are fragmented and contain small free blocks.
2. Relocate allocated blocks: The next step is to move the allocated blocks towards one end of the memory space, typically towards the lower addresses. This involves updating memory addresses in the process control blocks (PCBs) and any pointers or references to the memory blocks.
3. Adjust memory addresses: After relocating the allocated blocks, the memory addresses need to be adjusted to reflect the new positions. This may involve updating pointers, references, and any other data structures that store memory addresses.
4. Create a large block of free memory: As the allocated blocks are moved, the gaps between them are eliminated, creating a larger contiguous block of free memory.
5. Update memory management data structures: Finally, the memory management data structures, such as the free block list or bitmap, need to be updated to reflect the changes in the memory layout.
By compacting the memory and eliminating external fragmentation, compaction improves memory utilization and reduces the likelihood of memory allocation failures due to insufficient contiguous free memory. However, compaction can be a costly operation in terms of time and computational resources, especially if there are many allocated blocks that need to be moved. Therefore, it is typically used in situations where external fragmentation becomes a significant problem and memory compaction can be performed efficiently.
Consider the following page addresses stream frequency by executing the program with 3 frames. 1 2 3 1 2 5 8 7
By using optimal page replacement, number of page fault will be ....... and the number of page hit will be .......- a)3 6
- b)5 6
- c)2 6
- d)6 2
Correct answer is option 'D'. Can you explain this answer?
Consider the following page addresses stream frequency by executing the program with 3 frames. 1 2 3 1 2 5 8 7
By using optimal page replacement, number of page fault will be ....... and the number of page hit will be .......
By using optimal page replacement, number of page fault will be ....... and the number of page hit will be .......
a)
3 6
b)
5 6
c)
2 6
d)
6 2
|
|
Nandini Khanna answered |
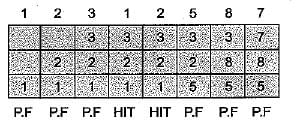
So, 6 page faults and 2 page hit.
Which of the following addressing modes, facilitates access to an operand whose location is defined relative to the beginning of the data structure in which it appears?- a)Ascending
- b)Sorting
- c)Index
- d)Indirect
Correct answer is option 'C'. Can you explain this answer?
Which of the following addressing modes, facilitates access to an operand whose location is defined relative to the beginning of the data structure in which it appears?
a)
Ascending
b)
Sorting
c)
Index
d)
Indirect
|
|
Luminary Institute answered |
Index addressing modes:
Index addressing modes facilitates access to an operand whose location is defined relative to the beginning of the data structure in which it appears.
Index addressing modes facilitates access to an operand whose location is defined relative to the beginning of the data structure in which it appears.
- In the indexed addressing mode, the content of a particular index register is appended to the address component of an instruction to obtain the effective address.
- The index register refers to a particular CPU register that contains an index value. The address field of an instruction specifies the starting address of any data array in memory.
- Using the index addressing mode, we get flexibility for specifying several locations of the memory.
Hence the correct answer is Index.
The page replacement policy that sometimes leads to more page faults when the size of the memory is increased is- a)FIFO
- b)LRU
- c)No such policy exists
- d)None of the above
Correct answer is option 'A'. Can you explain this answer?
The page replacement policy that sometimes leads to more page faults when the size of the memory is increased is
a)
FIFO
b)
LRU
c)
No such policy exists
d)
None of the above
|
|
Aashna Sen answered |
Explanation:
Page replacement algorithms are used in operating systems to manage the allocation of memory to different processes. When the size of memory is increased, it is expected that the number of page faults will decrease, as more pages can be stored in memory. However, sometimes increasing the size of memory can lead to more page faults, especially if a certain page replacement policy is used.
FIFO (First-In, First-Out) is a page replacement policy that works by replacing the oldest page in memory. When a new page is brought into memory, the oldest page is swapped out. If the size of memory is increased and the number of pages in memory exceeds the new size, the oldest pages will be removed first. This can result in more page faults, as the pages that are being removed may still be needed by the process.
For example, let's say that a process has 10 pages and the size of memory is 5 pages. When the process starts, the first 5 pages are brought into memory. As the process continues, more pages are brought into memory and older pages are swapped out using the FIFO policy. If the size of memory is increased to 7 pages, the first 2 pages that were swapped out using FIFO may still be needed by the process. This will result in more page faults, as these pages will need to be loaded back into memory.
In contrast, the LRU (Least Recently Used) policy works by replacing the least recently used page in memory. This policy is less likely to result in more page faults when the size of memory is increased, as the pages that are removed are less likely to be needed by the process.
Conclusion:
FIFO is a page replacement policy that can sometimes lead to more page faults when the size of memory is increased. This is because the oldest pages are removed first, which may still be needed by the process. LRU is a policy that is less likely to result in more page faults when the size of memory is increased.
Page replacement algorithms are used in operating systems to manage the allocation of memory to different processes. When the size of memory is increased, it is expected that the number of page faults will decrease, as more pages can be stored in memory. However, sometimes increasing the size of memory can lead to more page faults, especially if a certain page replacement policy is used.
FIFO (First-In, First-Out) is a page replacement policy that works by replacing the oldest page in memory. When a new page is brought into memory, the oldest page is swapped out. If the size of memory is increased and the number of pages in memory exceeds the new size, the oldest pages will be removed first. This can result in more page faults, as the pages that are being removed may still be needed by the process.
For example, let's say that a process has 10 pages and the size of memory is 5 pages. When the process starts, the first 5 pages are brought into memory. As the process continues, more pages are brought into memory and older pages are swapped out using the FIFO policy. If the size of memory is increased to 7 pages, the first 2 pages that were swapped out using FIFO may still be needed by the process. This will result in more page faults, as these pages will need to be loaded back into memory.
In contrast, the LRU (Least Recently Used) policy works by replacing the least recently used page in memory. This policy is less likely to result in more page faults when the size of memory is increased, as the pages that are removed are less likely to be needed by the process.
Conclusion:
FIFO is a page replacement policy that can sometimes lead to more page faults when the size of memory is increased. This is because the oldest pages are removed first, which may still be needed by the process. LRU is a policy that is less likely to result in more page faults when the size of memory is increased.
The data blocks of a very large file in the Unix file system are allocated using- a)contiguous allocation
- b)linked allocation
- c)indexed allocation
- d)an extension of indexed allocation
Correct answer is option 'D'. Can you explain this answer?
The data blocks of a very large file in the Unix file system are allocated using
a)
contiguous allocation
b)
linked allocation
c)
indexed allocation
d)
an extension of indexed allocation
|
|
Sanya Agarwal answered |
The Unix file system uses an extension of indexed allocation. It uses direct blocks, single indirect blocks, double indirect blocks and triple indirect blocks. Following diagram shows implementation of Unix file system.
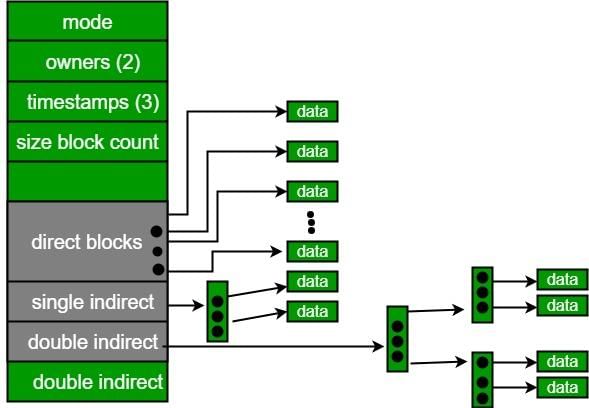
A hard disk has 63 sectors per track, 10 platters each with 2 recording surfaces and 1000 cylinders. The address of a sector is given as a triple (c, h, s), where c is the cylinder number, h is the surface number and s is the sector number. Thus, the 0th sector is addressed as (0, 0, 0), the 1st sector as (0, 0, 1), and so on The address <400,16,29> corresponds to sector number:- a)505035
- b)505036
- c)505037
- d)505038
Correct answer is option 'C'. Can you explain this answer?
A hard disk has 63 sectors per track, 10 platters each with 2 recording surfaces and 1000 cylinders. The address of a sector is given as a triple (c, h, s), where c is the cylinder number, h is the surface number and s is the sector number. Thus, the 0th sector is addressed as (0, 0, 0), the 1st sector as (0, 0, 1), and so on The address <400,16,29> corresponds to sector number:
a)
505035
b)
505036
c)
505037
d)
505038
|
|
Ravi Singh answered |
The data in hard disk is arranged in the shown manner. The smallest division is sector. Sectors are then combined to make a track. Cylinder is formed by combining the tracks which lie on same dimension of the platters. Read write head access the disk. Head has to reach at a particular track and then wait for the rotation of the platter so that the required sector comes under it. Here, each platter has two surfaces, which is the r/w head can access the platter from the two sides, upper and lower. So,<400,16,29> will represent 400 cylinders are passed(0-399) and thus, for each cylinder 20 surfaces (10 platters * 2 surface each) and each cylinder has 63 sectors per surface. Hence we have passed 0-399 = 400 * 20 * 63 sectors + In 400th cylinder we have passed 16 surfaces(0-15) each of which again contains 63 sectors per cylinder so 16 * 63 sectors. + Now on the 16th surface we are on 29th sector. So, sector no = 400x20x63 + 16×63 + 29 = 505037.
Using a larger block size in a fixed block size file system leads to :- a)better disk throughput but poorer disk space utilization
- b)better disk throughput and better disk space utilization
- c)poorer disk throughput but better disk space utilization
- d)poorer disk throughput and poorer disk space utilization
Correct answer is option 'A'. Can you explain this answer?
Using a larger block size in a fixed block size file system leads to :
a)
better disk throughput but poorer disk space utilization
b)
better disk throughput and better disk space utilization
c)
poorer disk throughput but better disk space utilization
d)
poorer disk throughput and poorer disk space utilization
|
|
Sanya Agarwal answered |
Using larger block size makes disk utilization poorer as more space would be wasted for small data in a block. It may make throughput better as the number of blocks would decrease. A larger block size guarantees that more data from a single file can be written or read at a time into a single block without having to move the disk ́s head to another spot on the disk. The less time you spend moving your heads across the disk, the more continuous reads/writes per second. The smaller the block size, the more frequent it is required to move before a read/write can occur. Larger block size means less number of blocks to fetch and hence better throughput. But larger block size also means space is wasted when only small size is required and hence poor utilization.

Which of the following statements about synchronous and asynchronous I/O is NOT true?- a)An ISR is invoked on completion of I/O in synchronous I/O but not in asynchronous I/O
- b)In both synchronous and asynchronous I/O, an ISR (Interrupt Service Routine) is invoked after completion of the I/O
- c)A process making a synchronous I/O call waits until I/O is complete, but a process making an asynchronous I/O call does not wait for completion of the I/O
- d)In the case of synchronous I/O, the process waiting for the completion of I/O is woken up by the ISR that is invoked after the completion of I/O
Correct answer is option 'B'. Can you explain this answer?
Which of the following statements about synchronous and asynchronous I/O is NOT true?
a)
An ISR is invoked on completion of I/O in synchronous I/O but not in asynchronous I/O
b)
In both synchronous and asynchronous I/O, an ISR (Interrupt Service Routine) is invoked after completion of the I/O
c)
A process making a synchronous I/O call waits until I/O is complete, but a process making an asynchronous I/O call does not wait for completion of the I/O
d)
In the case of synchronous I/O, the process waiting for the completion of I/O is woken up by the ISR that is invoked after the completion of I/O
|
|
Sanya Agarwal answered |
An interrupt service routine will be invoked after the completion of I/O operation and it will place process from block state to ready state, because process performing I/O operation was placed in blocked state till the I/O operation was completed in Synchronous I/O. However, process performing I/O will not be placed in the block state and process continues to execute the remaining instructions in Asynchronous I/O, because handler function will be registered while performing the I/O operation, when the I/O operation completed signal mechanism is used to notify the process that data is available. So, option (B) is false.
In Magnetic Disks Structures, The surface of a platter is logically divided into circular______- a)sectors
- b)arms
- c)tracks
- d)spindle
Correct answer is option 'C'. Can you explain this answer?
In Magnetic Disks Structures, The surface of a platter is logically divided into circular______
a)
sectors
b)
arms
c)
tracks
d)
spindle
|
|
Saranya Banerjee answered |
Magnetic Disks Structures:
A magnetic disk is a storage device that uses magnetization to store and retrieve digital data. It consists of one or more rotating disks coated with magnetic material and read/write heads to access the data. The surface of a platter in magnetic disks structures is logically divided into circular tracks.
Circular Tracks:
The surface of a platter is logically divided into circular tracks. These tracks are concentric circles on the surface of the disk. The tracks are numbered from the outermost track to the innermost track. Each track is further divided into sectors, which are pie-shaped wedges on the surface of the disk.
Sectors:
Each sector on a track stores a fixed amount of data. The number of sectors on a track can vary depending on the disk's format and capacity. Sectors are numbered sequentially starting from 0 to the maximum number of sectors on a track.
Conclusion:
In conclusion, the surface of a platter in magnetic disks structures is logically divided into circular tracks, which are concentric circles on the surface of the disk. Each track is further divided into sectors, which are pie-shaped wedges on the surface of the disk. Sectors are numbered sequentially starting from 0 to the maximum number of sectors on a track. By dividing the surface of the platter into circular tracks and sectors, it becomes easier to organize and access the data stored on the disk.
A magnetic disk is a storage device that uses magnetization to store and retrieve digital data. It consists of one or more rotating disks coated with magnetic material and read/write heads to access the data. The surface of a platter in magnetic disks structures is logically divided into circular tracks.
Circular Tracks:
The surface of a platter is logically divided into circular tracks. These tracks are concentric circles on the surface of the disk. The tracks are numbered from the outermost track to the innermost track. Each track is further divided into sectors, which are pie-shaped wedges on the surface of the disk.
Sectors:
Each sector on a track stores a fixed amount of data. The number of sectors on a track can vary depending on the disk's format and capacity. Sectors are numbered sequentially starting from 0 to the maximum number of sectors on a track.
Conclusion:
In conclusion, the surface of a platter in magnetic disks structures is logically divided into circular tracks, which are concentric circles on the surface of the disk. Each track is further divided into sectors, which are pie-shaped wedges on the surface of the disk. Sectors are numbered sequentially starting from 0 to the maximum number of sectors on a track. By dividing the surface of the platter into circular tracks and sectors, it becomes easier to organize and access the data stored on the disk.
Consider the process track request are 98, 183, 37, 122, 14, 124, 14, 124, 65, 67 and the initial seek is 53. What is the total number of seeks for the C-Look algorithm?
Correct answer is '322'. Can you explain this answer?
Consider the process track request are 98, 183, 37, 122, 14, 124, 14, 124, 65, 67 and the initial seek is 53. What is the total number of seeks for the C-Look algorithm?
|
|
Sudhir Patel answered |
The given data,
The process track request are= 98, 183, 37, 122, 14, 124, 14, 124, 65, 67
The initial seek = 53
C-Look algorithm:
The process track request are= 98, 183, 37, 122, 14, 124, 14, 124, 65, 67
The initial seek = 53
C-Look algorithm:
Total number of seeks= ( 183-53 )+(183-14) +(37-14)
Total number of seeks= 322
Hence the correct answer is 322.
Total number of seeks= 322
Hence the correct answer is 322.
Consider a storage disk with 4 platters (numbered as 0, 1, 2 and 3), 200 cylinders (numbered as 0, 1, … , 199), and 256 sectors per track (numbered as 0, 1, … , 255). The following 6 disk requests of the form [sector number, cylinder number, platter number] are received by the disk controller at the same time: [120, 72, 2] , [180, 134, 1] , [60, 20, 0] , [212, 86, 3] , [56, 116, 2] , [118, 16, 1] Currently the head is positioned at sector number 100 of cylinder 80, and is moving towards higher cylinder numbers. The average power dissipation in moving the head over 100 cylinders is 20 milliwatts and for reversing the direction of the head movement once is 15 milliwatts. Power dissipation associated with rotational latency and switching of head between different platters is negligible. The total power consumption in milliwatts to satisfy all of the above disk requests using the Shortest Seek Time First disk scheduling algorithm is _______.
Correct answer is '85'. Can you explain this answer?
Consider a storage disk with 4 platters (numbered as 0, 1, 2 and 3), 200 cylinders (numbered as 0, 1, … , 199), and 256 sectors per track (numbered as 0, 1, … , 255). The following 6 disk requests of the form [sector number, cylinder number, platter number] are received by the disk controller at the same time: [120, 72, 2] , [180, 134, 1] , [60, 20, 0] , [212, 86, 3] , [56, 116, 2] , [118, 16, 1] Currently the head is positioned at sector number 100 of cylinder 80, and is moving towards higher cylinder numbers. The average power dissipation in moving the head over 100 cylinders is 20 milliwatts and for reversing the direction of the head movement once is 15 milliwatts. Power dissipation associated with rotational latency and switching of head between different platters is negligible. The total power consumption in milliwatts to satisfy all of the above disk requests using the Shortest Seek Time First disk scheduling algorithm is _______.
|
|
Sudhir Patel answered |
Total head movements in SSTF= (86−80)+(86−72)+(134−72)+(134−16)=200
Power dissipated in moving 100 cylinder = 20mW
Power dissipated by 200 movements = 0.2∗200=40mW = P
Power dissipated in reversing head direction once= 15mW
Number of times head changes its direction= 3
Power dissipated in reversing head direction = 3∗15= 45mW = Q
Total Power Consumption is P + Q = 85mW
Power dissipated in moving 100 cylinder = 20mW
Power dissipated by 200 movements = 0.2∗200=40mW = P
Power dissipated in reversing head direction once= 15mW
Number of times head changes its direction= 3
Power dissipated in reversing head direction = 3∗15= 45mW = Q
Total Power Consumption is P + Q = 85mW
Dak bearing a security grading confidential, secret etc is known as?- a)Secret dak
- b)Classified dak
- c)Closed Dak
- d)Desk Dak
Correct answer is option 'B'. Can you explain this answer?
Dak bearing a security grading confidential, secret etc is known as?
a)
Secret dak
b)
Classified dak
c)
Closed Dak
d)
Desk Dak
|
|
Sudhir Patel answered |
Dak:
All communication received/issued by an office/department through dak.
All communication received/issued by an office/department through dak.
Classified dak:
Dak bearing security grading confidential, secret, etc. is called Classified dak.
Dak bearing security grading confidential, secret, etc. is called Classified dak.
Consider a disk pack with 16 surfaces, 128 tracks per surface and 256 sectors per track. 512 bytes of data are stores in a bit serial manner in a sector. The capacity of the disk pack and the number of bits required to specify a particular sector in the disk are respectively- a)256 Mbyte, 19 bits
- b)256 Mbyte, 28 bit
- c)512 Mbyte, 20 bits
- d)64 Gbyte, 28 bits
Correct answer is option 'A'. Can you explain this answer?
Consider a disk pack with 16 surfaces, 128 tracks per surface and 256 sectors per track. 512 bytes of data are stores in a bit serial manner in a sector. The capacity of the disk pack and the number of bits required to specify a particular sector in the disk are respectively
a)
256 Mbyte, 19 bits
b)
256 Mbyte, 28 bit
c)
512 Mbyte, 20 bits
d)
64 Gbyte, 28 bits
|
|
Anshu Mehta answered |
Capacity of the Disk Pack:
Given:
- Number of surfaces = 16
- Number of tracks per surface = 128
- Number of sectors per track = 256
- Data stored in a sector = 512 bytes
To calculate the capacity of the disk pack, we need to multiply the number of surfaces, tracks per surface, sectors per track, and the data stored in a sector.
Capacity of the disk pack = Number of surfaces × Number of tracks per surface × Number of sectors per track × Data stored in a sector
Capacity of the disk pack = 16 × 128 × 256 × 512 bytes
To convert bytes to megabytes, we divide the result by 1,048,576 (1 MB = 1,048,576 bytes).
Capacity of the disk pack = (16 × 128 × 256 × 512) / 1,048,576 MB
Calculating this equation gives us:
Capacity of the disk pack = 256 MB
Number of Bits to Specify a Sector:
Given:
- Number of sectors per track = 256
To calculate the number of bits required to specify a particular sector in the disk, we need to find the minimum number of bits required to represent 256 sectors.
The minimum number of bits required to represent n sectors is given by the formula:
Number of bits = log2(n)
Number of bits = log2(256)
Using a calculator, we find:
Number of bits = 8 bits
Therefore, the number of bits required to specify a particular sector in the disk is 8 bits.
Conclusion:
The capacity of the disk pack is 256 Mbyte and the number of bits required to specify a particular sector in the disk is 8 bits. Therefore, the correct answer is option A: 256 Mbyte, 19 bits.
Given:
- Number of surfaces = 16
- Number of tracks per surface = 128
- Number of sectors per track = 256
- Data stored in a sector = 512 bytes
To calculate the capacity of the disk pack, we need to multiply the number of surfaces, tracks per surface, sectors per track, and the data stored in a sector.
Capacity of the disk pack = Number of surfaces × Number of tracks per surface × Number of sectors per track × Data stored in a sector
Capacity of the disk pack = 16 × 128 × 256 × 512 bytes
To convert bytes to megabytes, we divide the result by 1,048,576 (1 MB = 1,048,576 bytes).
Capacity of the disk pack = (16 × 128 × 256 × 512) / 1,048,576 MB
Calculating this equation gives us:
Capacity of the disk pack = 256 MB
Number of Bits to Specify a Sector:
Given:
- Number of sectors per track = 256
To calculate the number of bits required to specify a particular sector in the disk, we need to find the minimum number of bits required to represent 256 sectors.
The minimum number of bits required to represent n sectors is given by the formula:
Number of bits = log2(n)
Number of bits = log2(256)
Using a calculator, we find:
Number of bits = 8 bits
Therefore, the number of bits required to specify a particular sector in the disk is 8 bits.
Conclusion:
The capacity of the disk pack is 256 Mbyte and the number of bits required to specify a particular sector in the disk is 8 bits. Therefore, the correct answer is option A: 256 Mbyte, 19 bits.
Match the following w.r.t. Input/Output management
- a)(1)
- b)(2)
- c)(3)
- d)(4)
Correct answer is option 'A'. Can you explain this answer?
Match the following w.r.t. Input/Output management
a)
(1)
b)
(2)
c)
(3)
d)
(4)

|
Cstoppers Instructors answered |
- Device controller performs data transfer.
- Device driver process I/O request.
- Inturrupt handler Extracts information from the controller register and store it in data buffer
- Kernel I/O subsystem performs I/O scheduling./li> So, option (A) is correct.
Consider a file currently consisting of 50 blocks. Assume that the file control block and the index block is already in memory. If a block is added at the end (and the block information to be added is stored in memory), then how many disk I/O operations are required for indexed (single-level) allocation strategy?- a)1
- b)101
- c)27
- d)0
Correct answer is option 'A'. Can you explain this answer?
Consider a file currently consisting of 50 blocks. Assume that the file control block and the index block is already in memory. If a block is added at the end (and the block information to be added is stored in memory), then how many disk I/O operations are required for indexed (single-level) allocation strategy?
a)
1
b)
101
c)
27
d)
0
|
|
Jay Basu answered |
Indexed (Single-Level) Allocation Strategy
In indexed allocation, a separate index block is used to store the addresses of the data blocks. Each data block is assigned a unique index in the index block, allowing for direct access to the data blocks.
Given:
- File consists of 50 blocks
- File control block (FCB) and index block are already in memory
- A block is added at the end and the block information is stored in memory
Calculation:
To determine the number of disk I/O operations required, we need to consider the following:
1. Retrieve the index block from memory: 1 disk I/O operation
2. Update the index block with the address of the new data block: 1 disk I/O operation
3. Write the updated index block back to disk: 1 disk I/O operation
Since the index block is already in memory, we only need to perform disk I/O operations to update and write back the index block. The data block to be added is stored in memory, so no additional disk I/O operation is required to retrieve it.
Therefore, the total number of disk I/O operations required for indexed allocation in this scenario is 1 (to write the updated index block back to disk).
Answer:
The correct answer is option A) 1.
In indexed allocation, a separate index block is used to store the addresses of the data blocks. Each data block is assigned a unique index in the index block, allowing for direct access to the data blocks.
Given:
- File consists of 50 blocks
- File control block (FCB) and index block are already in memory
- A block is added at the end and the block information is stored in memory
Calculation:
To determine the number of disk I/O operations required, we need to consider the following:
1. Retrieve the index block from memory: 1 disk I/O operation
2. Update the index block with the address of the new data block: 1 disk I/O operation
3. Write the updated index block back to disk: 1 disk I/O operation
Since the index block is already in memory, we only need to perform disk I/O operations to update and write back the index block. The data block to be added is stored in memory, so no additional disk I/O operation is required to retrieve it.
Therefore, the total number of disk I/O operations required for indexed allocation in this scenario is 1 (to write the updated index block back to disk).
Answer:
The correct answer is option A) 1.
Which table is used in MS DOS for linked list allocation?- a)TLB
- b)Page Table
- c)FAT
- d)Index Table
Correct answer is option 'C'. Can you explain this answer?
Which table is used in MS DOS for linked list allocation?
a)
TLB
b)
Page Table
c)
FAT
d)
Index Table
|
|
Sudhir Patel answered |
- At the time of formatting, the FAT is statically allocated. The table is a linked list of entries for each cluster, a contiguous area of disk storage.
- FAT table is used in MSDOS for linked list allocation.
- The File Allocation Table is used by the file system to define chains of data storage areas associated with a file (FAT). At the time of formatting, the FAT is assigned statically. Each cluster, or contiguous area of disc storage, is represented by a linked list of entries in the table.
Hence the correct answer is FAT.
A device with data transfer rate 10 KB/sec is connected to a CPU. Data is transferred byte-wise. Let the interrupt overhead be 4 microsec. The byte transfer time between the device interface register and CPU or memory is negligible. What is the minimum performance gain of operating the device under interrupt mode over operating it under program controlled mode?- a)15
- b)25
- c)35
- d)45
Correct answer is option 'B'. Can you explain this answer?
A device with data transfer rate 10 KB/sec is connected to a CPU. Data is transferred byte-wise. Let the interrupt overhead be 4 microsec. The byte transfer time between the device interface register and CPU or memory is negligible. What is the minimum performance gain of operating the device under interrupt mode over operating it under program controlled mode?
a)
15
b)
25
c)
35
d)
45
|
|
Sanya Agarwal answered |
In programmed I/O, CPU does continuous polling, To transfer 1B CPU polls for 10^-4 sec = 10^2 micro-sec of processing In interrupt mode CPU is interrupted on completion of i\o, To transfer 1B CPU does 4 micro-sec of processing(since transfer time between other components is negligible). Gain = 10^2 / 4 = 25
Chapter doubts & questions for File Systems - Operating System 2025 is part of Computer Science Engineering (CSE) exam preparation. The chapters have been prepared according to the Computer Science Engineering (CSE) exam syllabus. The Chapter doubts & questions, notes, tests & MCQs are made for Computer Science Engineering (CSE) 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises, MCQs and online tests here.
Chapter doubts & questions of File Systems - Operating System in English & Hindi are available as part of Computer Science Engineering (CSE) exam.
Download more important topics, notes, lectures and mock test series for Computer Science Engineering (CSE) Exam by signing up for free.
Operating System
10 videos|141 docs|33 tests
|
|
© EduRev
|
Education Revolution
|



|









Signup to see your scores
go up
within 7 days!
within 7 days!
Takes less than 10 seconds to signup